At the highest level, technical SEO is the act of setting up your site so that it is accessible to search engines, tells them clearly what your site and pages are about, loads quickly for users and search engines, and provides a great experience through all of that.
There is first basic technical SEO, which involves building your site on a platform that the search engines can crawl and index. Some platforms, like WordPress, may not be sexy but they are proven and have many resources available to help you optimize it. Out of the box, the platform is pretty SEO-friendly. Similar platforms that have long been used and are relatively SEO-friendly out of the box are SquareSpace and Joomla, though each has their own challenges to SEO as well.
Other technologies you might use and platforms that you might run your SaaS marketing site on are less SEO friendly. Technologies like React and Vue, both very popular JavaScript frameworks, can be SEO friendly (as can Angular), but you have to know to server-side render any content you want indexed and then constantly keep up with changes to search engine crawling abilities.
Google is pretty good at JavaScript these days, though server-side rendering for React/Vue and using something like Brombone for Angular is still necessary. Bing, on the other hand, can’t really crawl JavaScript.
So what would we recommend for a marketing site that is SEO friendly?
First, WordPress. It’s trusted, it’s simple, it’s easy to configure. There are security concerns but those are also quite easily dealt with. The great thing about WordPress is that most front end and full stack developers have experience on it and can learn WordPress’s slightly unique version of PHP. You can also fairly easily find good WordPress developers should you be in a pinch. We recommend hosting on Kinsta (our current host) or WPengine (our previous host) as they are dedicated to WordPress hosting.
Click here to check out Kinsta for your WordPress hosting needs
Second, Craft. Craft is a relative newcomer to the CMS space, but increasingly more SaaS sites are using it for their marketing site for its ease of use. You have to pay for a license (around $299 per year) and self-host though they do have a few recommended hosts.
Third, SquareSpace. SquareSpace is not as extendable as WordPress, as it is not self-hosted. But it is simple and easy to use and has most SEO considerations baked into it. It’s less extendable, but if you’re just trying to get a site up and you don’t have WordPress experience then this might be a good first choice.
Fourth, build your own using a trusted technology like PHP. As I’ve already said, you can use whatever technology you want but each has its own challenges. I rarely recommend doing this as the other three mentioned above work so well and require vastly less upkeep.
One area that I constantly have to clarify with SaaS teams is this – search engines do not crawl your logged in application. If you put content behind a log in or paywall, then you do not have to worry about them crawling those URLs.
Conversely, if you want content to be crawled then do not put it behind a login wall! Sure there are ways to show that you have logged in content that can still be accessed sometimes by logged out users (think about news publications with paywalls), but 99.9% of SaaS apps do not have to think about this.
If you are concerned about your web app being crawled, then there are ways to ensure that it is not crawled such as:
I see many SaaS companies use something like WordPress for their “marketing site”, and then a custom web app on a subdomain. This is a great way to handle your dual needs and not harm your SEO.
Let’s talk for a while about technical and on-page SEO. We’ll also talk about some tools that you can use for diagnosing onsite errors and issues where you can improve your site to get more traffic. This section should also be taken in concert with the following chapter on keyword research, because all the technical SEO in the world without great keyword research is meaningless.
I am covering technical SEO before keyword research because most SaaS companies are very technically driven. I want to lay the groundwork of how to think about SEO and what matters before we get into driving SEO growth with keyword research, content, and link building.
For every page on your site, there are meta elements in your documents’s <head> that should be present to help the search engines understand what your page is about. Note that these are separate from the on-page SEO elements mentioned above, such as H1s/H2s.
The meta elements you need to have on each page on your site are:
To properly optimize your pages for SEO, these are the basics that you must have along with proper HTML formatting of H1s/H2s/etc described above.
Your title tag is useful for two things for SEO. First, it is one of the strongest signals to the search engines what your page is about. Second, if you write good titles then you can (in partnership with the meta description) entice clicks to your site even if you are not ranked in the first position.
To be optimally optimized for SEO, your title tags must be:
Here is an example for [proposal template]:
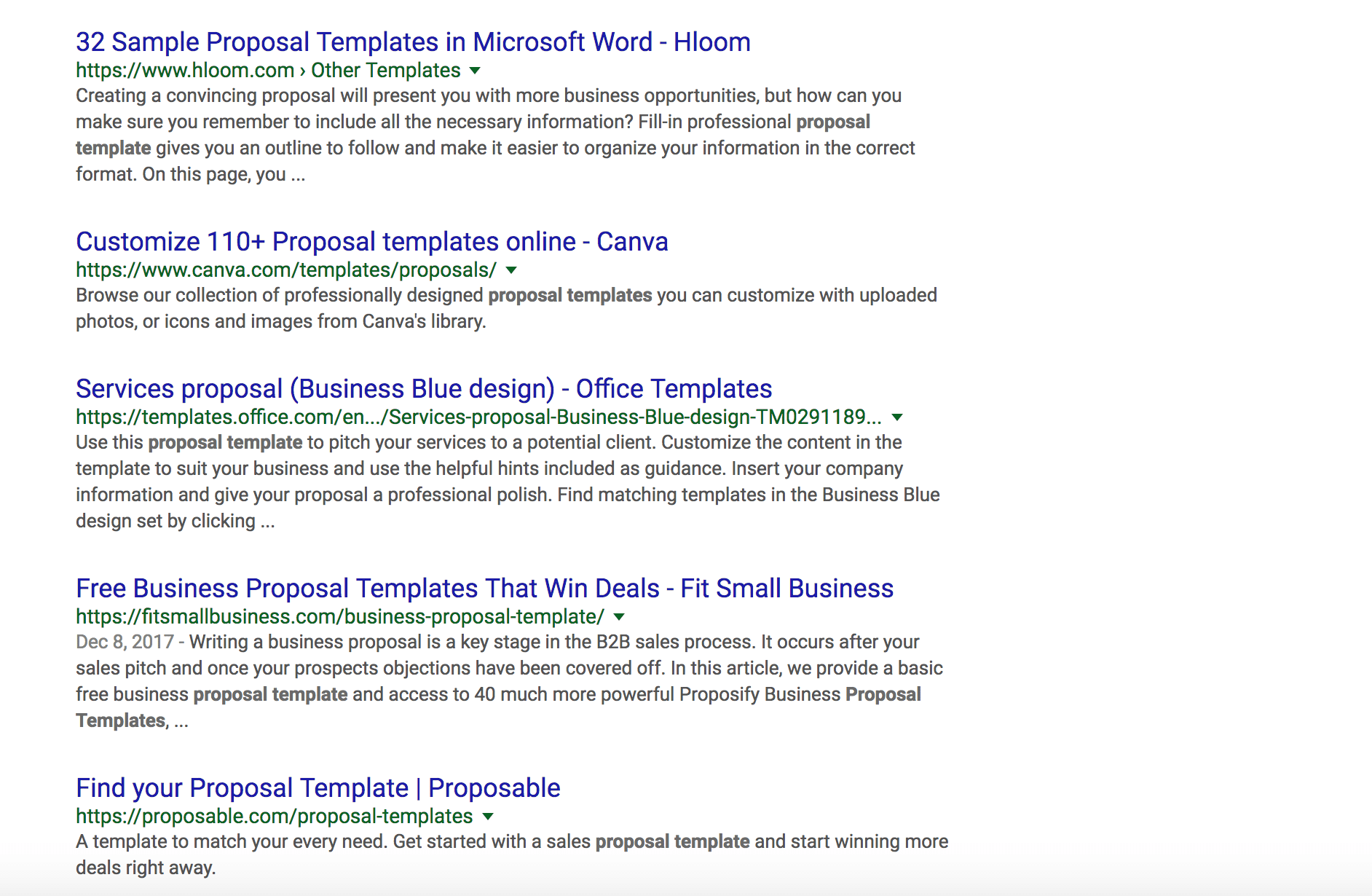
Which one would you click? It depends on if you are searching for proposal template ideas, a ready-to-use template, and which software you are using to create them. Reality is that a lot of businesses still use Word for creating their templates, but there is an opportunity here for Proposable to make a better title tag that will entice more clicks and help them move people away from Microsoft Word.
The meta description is the that appears below the blue link in the SERPs. Historically the meta description would be truncated around 160 characters, though in late 2017 Google announced that they were expanding this across their search results to around 300 characters.
The meta description is not used in rankings, but it does play a key role in enticing clicks through to your website. It is important to understand if the query for which the page is ranking is transactional or informational, and that informs your meta description strategy.
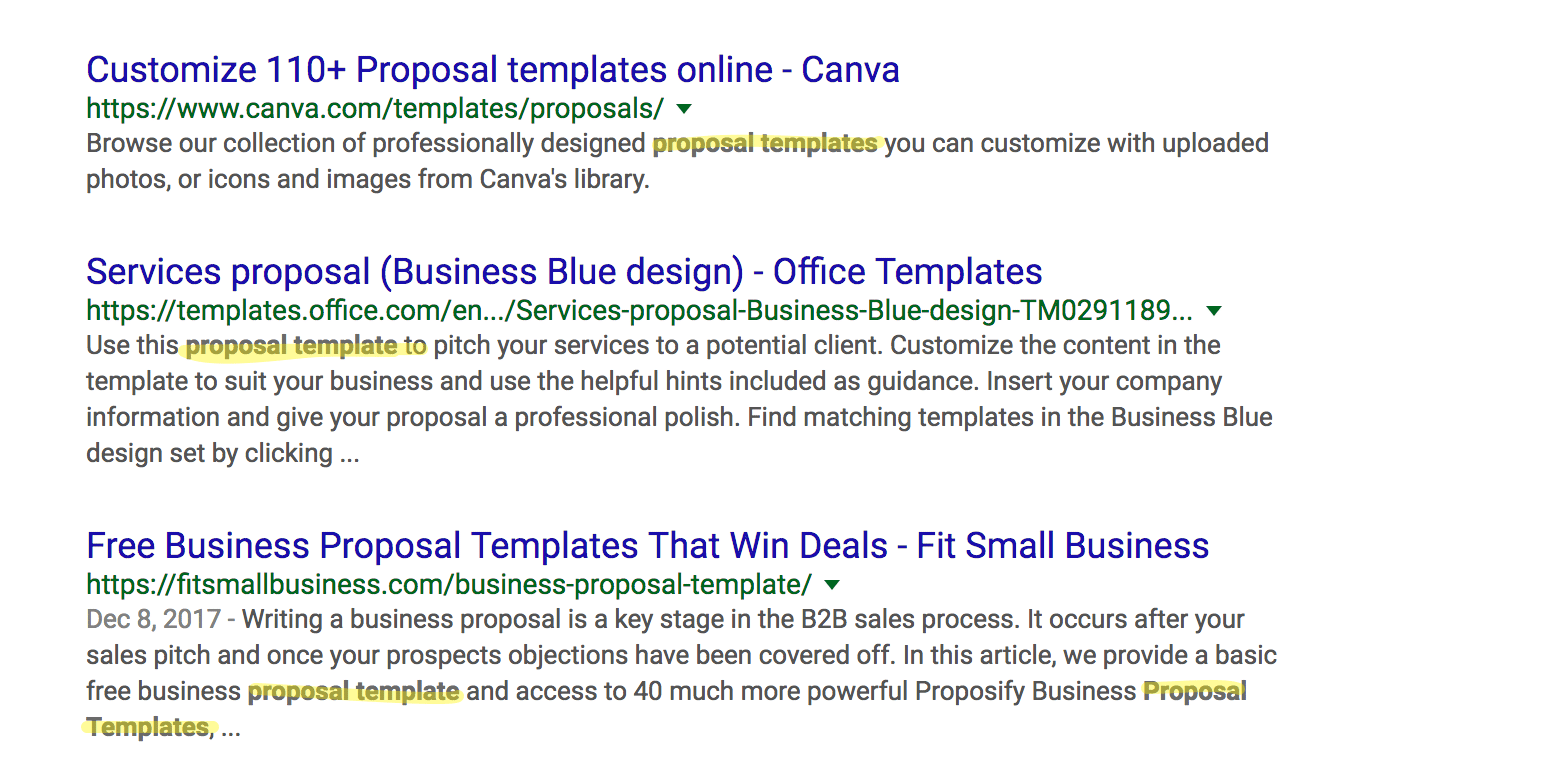
Using the [proposal templates] example from above, you can see that the search engines bold the searched term when it appears in the meta description. Historically, this has correlated to increased click throughs, though these days when rich features like review stars are present this helps less. It is still worthwhile to consider if your meta description is accurately describing what is on your page, especially for transactional queries:
The canonical tag is a meta tag provided by the search engines to help website owners control potential duplicate content on their website. The canonical tag is a suggestion to the search engines that tells them the original source of the content.
In almost every case, a canonical tag is self-referential to the page. So getcredo.com/blog/ canonicals to itself with this:
<link rel=”canonical” href=”https://getcredo.com/blog/”>
Canonicals can also be used cross-domain. When you publish content on your website and then on another, such as Medium, then to avoid duplicate content issues (where the non-original source may outrank the original) a rel-canonical tag should be used. Medium does this by default, though many other publishers do not.
Many marketing site platforms do canonicals by default, such as WordPress using Yoast SEO.
If you’re just starting off, don’t worry about advanced canonicals. What you need to do is make sure that you have a consistent URL schema set and that your canonical points to that page from other URLs that serve the same content.
For example, maybe you use a technology that makes it impossible to redirect all UPPERCASE and Sentence-Case URLs to the main /this-is-our-url URL. While ideally you would redirect all other permutations (www/non-www, trailing slash/non-trailing slash, UPPERCASE/Sentence-Case) into your one canonical URL of /this-is-our-url, if your technology does not allow it right now then you need to implement the canonicals.
Best practice is also to self-canonical URLs to themselves with the absolute path. Your URL /this-is-our-url would then have this (assuming you use HTTPS, www, and a trailing slash):
<link rel=”canonical” href=”https://www.site.com/this-is-our-url”>
The meta robots tag is used to control indexation on an individual page level. It looks like this:
<meta name=”robots” content=”index, follow”>
The default is “index, follow”, meaning the search engines should a) index the page and b) follow the links from the page to other pages on the site, passing them link equity to help them rank.
If you do not want a page to be indexed, then you can set the meta robots tag to the following:
<meta name=”robots” content=”noindex, follow”>
This means that the page may still be crawled by the search engines, but it will not be included in their index nor findable in the search results. This is by design. If you want the page to be indexed, then set meta robots to index.
The types of pages you may not want indexed are:
One of the most important parts of technical SEO is controlling indexation of your pages so that the search engines are able to rank the right page for the right search query. This coupled with keyword research and proactively developing content to attract top, middle, and bottom of funnel users is singlehandedly the best thing you can do for SEO once you have your page templates properly formatted, URLs settled, and canonicals implemented correctly.
If you’re a web developer, then you should know about the robots.txt file. This file is used to control indexation on a broader level than meta robots. When a page or subfolder is blocked in robots.txt, that page is no longer crawled by the search engines. When a subfolder is blocked, then no page within that subfolder is crawled by the search engines unless a specific page is specified to be allowed.
The robots.txt is a sledgehammer to control indexation. For SaaS apps, it should most commonly be used for your logged-in application in case someone should link to a logged in page externally. You do not want the search engines to be wasting their crawl time on your pages that are only available logged in. If your app uses subdomains for users to display content publicly (such as https://site.yourservice.com), then you should not block those subdomains in robots.txt!
This file is included in the root of your site and can be found here:
https://www.domain.com/robots.txt
It has two main purposes:
The robots.txt file by default looks something like this (this from a WordPress installation):
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.phpSitemap: https://www.domain.com/sitemap_index.xml
If you already have pages in the search engine index that you do not want indexed or crawled, then the fix is not as simple as blocking the page in robots.txt. This will stop the search engines from crawling the page, but will not remove the page from the index. To remove a section of your site from the search engines and stop them from crawling, first implement a meta robots noindex and then block in robots.txt once the pages have dropped from the index.
Most sites use parameters to handle filtering or sometimes to build your URLs. While I do not ever recommend using parameters for your indexable URLs that you would like to rank (instead of using site.com/type?param=keyword, use clean URLs like site.com/folder/slug-url), filtering is often completely unavoidable on your website.
Therefore, you need to control how the search engines access these pages so that you are not inadvertently serving multiple (sometimes many as 4-6) exact or near-exact duplicates of the same content. When this happens, the search engines often do not understand which version to rank, and thus you risk them ranking the wrong URL worse than they’d rank the correct URL should you send the right signals.
You can control parameters two ways (and I recommend using both)
Like anything in SEO, the “right” answer to solving specific problems is “it depends”. Depending on the parameter, you will deal with it in different ways.
Here is how to think about when to use which solution.
Controlling parameters via Search Console/Webmaster Tools is a no-brainer that should always be taken advantage of. Each search engine will tell you the parameters they have discovered, which you can then directly tell them what to do with that specific parameter.
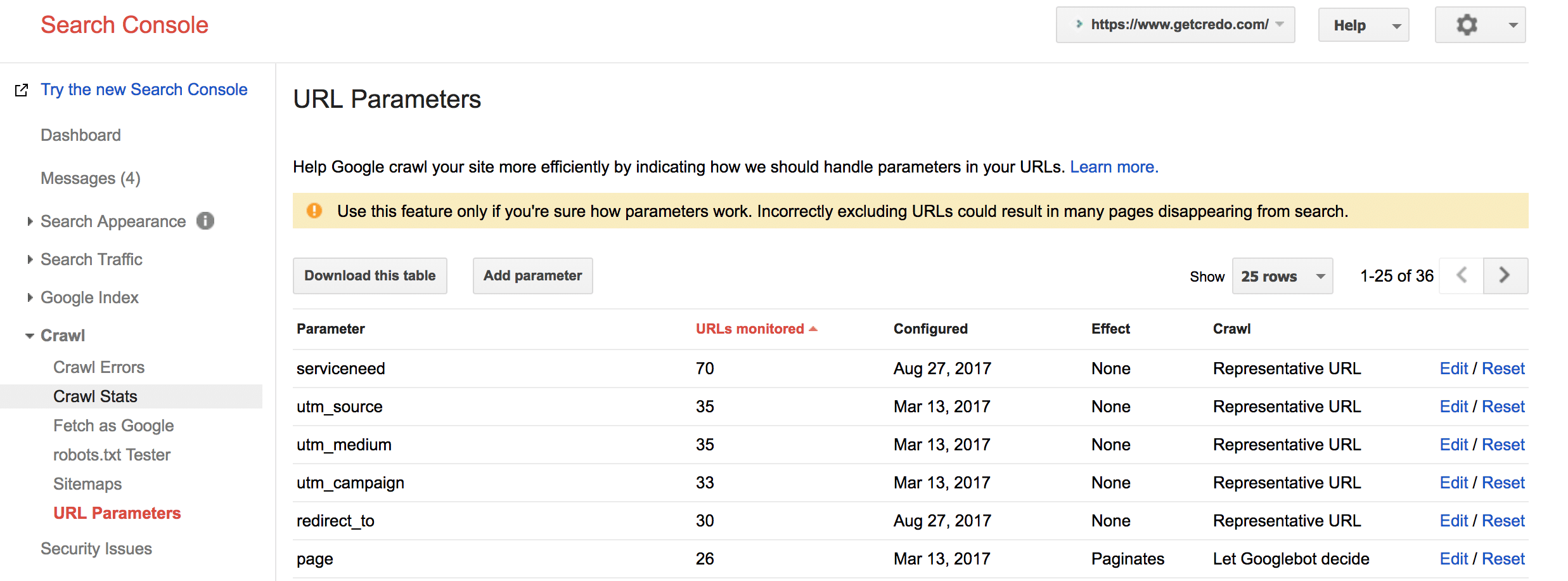
For each parameter discovered, you can specify if the parameter:
If the parameter tracks usage, then the search engines will pick one representative URL which should be your URL that is most often linked on your site. If you find that they are indexing the wrong URL then you can also apply a canonical tag to direct them to the URL you would like them to rank, though you should also change your internal linking to link to that URL and not a parameter version.
If the parameter changes page content, then you should choose what the parameter does (Sorts, Narrows, Specifies, Translates, Paginates, Other) and then what the search engines should do. I normally leave the directive as “Let Googlebot decide”, but if it a logged in URL for example and they are discovering/crawling it then I will tell them to crawl No URLs.
Use canonical tags with parameters when you have filtering options on the front end of the site that you do not want indexed. For example, site.com/slug-url?sort=ascending&date=today would canonical back to site.com/slug-url because your two parameters are not new content that you want the search engines to index. These URLs are not showing new content, but rather sorting and specifying a specific date. If you want the specific date indexed, then the correct solution is to create a specific URL path (eg site.com/slug-url/date) instead of using a parameter.
There are two main types of redirects that are used in SEO, and knowing the difference is important to your SEO success.
The two are:
There is always debate within the SEO world about redirects. It is one of those arguments that never dies, similar to “which technology should I use for my web app” conversations within the SaaS world.
While people will debate it, the answer to “which redirect should I use and when?” is answered in the definitions of the two redirects.
If your URL is moving permanently, then you should use a 301 redirect. This has been proven time and time again to pass link equity to the new URL so that any links pointing to the old URL now count towards the new URL ranking. A 301 redirect will also remove the old URL from the index and the new URL will begin ranking.
If your URL is moving temporarily (such as for maintenance) and you expect it to come back in short order, then use a 302 redirect. An example of when to use a 302 redirect on a SaaS marketing site would be if you were removing a feature, and thus its dedicated landing page, for a while but plan to bring it back. You could 302 redirect the feature URL to your /features (or equivalent) page and remove the individual feature page from XML sitemaps and internal linking. The URL will not drop from the search index, but it also will not rank as well as before. When you bring back the page, undo the 302 redirect.
Takeaway: do not debate if a 301 or 302 redirect will pass link equity or not. While your tech stack may default to one, it is always possible to fix it to be able to apply the correct redirect. If you are current redirecting via 302 instead of 301 for permanent redirects, get an understanding of the links pointing to those pages to understand how many links (and thus potential rankings) you are leaving on the table.
XML sitemaps are your direct way to tell the search engines about your pages and gain an understanding of how well the search engines are indexing the content on your site. In Google Search Console this is found under Crawl > Sitemaps, and in Bing Webmaster Tools it is found under Dashboard > Configure my site > Sitemaps.
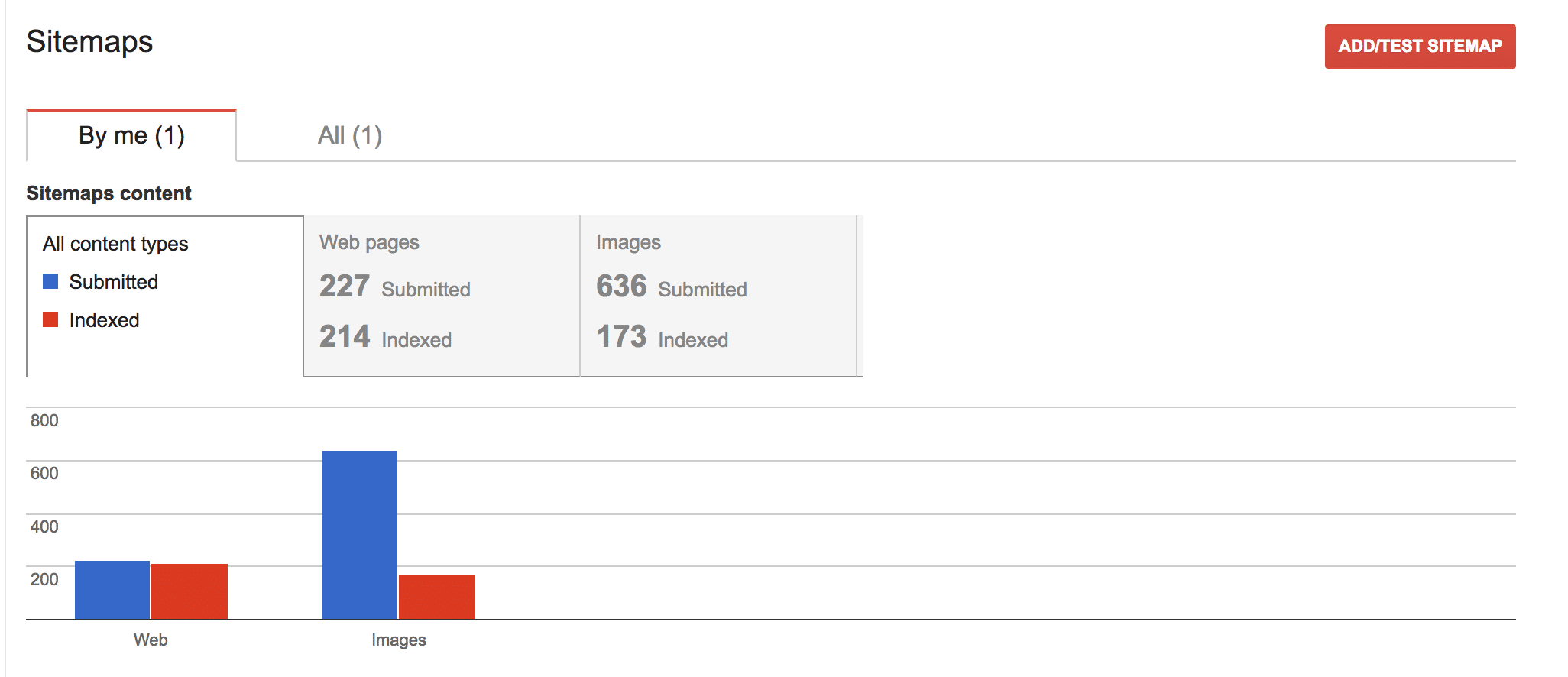
The XML sitemap structure can be found on Sitemaps.org. You should take the time to review that site because there are different XML sitemap options depending on the types of content you have on your site, such as video.
The default/base XML sitemap structure is this:
<?xml version=”1.0″ encoding=”UTF-8″?>
<urlset xmlns=”http://www.sitemaps.org/schemas/sitemap/0.9″>
<url>
<loc>http://www.example.com/</loc>
<lastmod>2005-01-01</lastmod>
<changefreq>monthly</changefreq>
<priority>0.8</priority>
</url>
</urlset>
Your XML sitemaps should be dynamically generated, meaning that every time a new page/post is published or removed from your site, the sitemap should update as well. Sitemaps should only serve URL that return a 200 status code and are the canonical URL. If a URL redirects, is blocked in robots.txt, or canonicals to another page then it should not be included. Too many non-200 URLs can cause the search engines to not trust your sitemaps, which results in worse indexation.
Most SaaS companies can get away with basic XML sitemaps because you realistically have 50-100 URLs available logged out. We do recommend dividing up your sitemaps by type of page so that you can view indexation for these buckets, such as features pages or blog posts. This can help you diagnose issues with ranking and driving traffic.
You can find a deeper dive into XML sitemaps on Credo here.
If you are looking to get basic SEO tracking in place for technical SEO purposes, we advice you to get a subscription to a few SEO tools that can monitor your SEO basics and alert you when you have issues.
These are the basic tools to have in your toolbelt to help you with identifying major SEO issues and measuring traffic/conversions/health of your marketing.
Check out all of Credo’s recommended tools for SEO, lead generation, and more.
Check out SEO companies on Credo
This page last updated on February 17, 2023 by John Doherty
Download the SaaS SEO guide in PDF format
Oops! We could not locate your form.
Drive results for your marketing needs with the Credo network. Get started today (it's free and there is no obligation)!
 Loading...
Loading...