Imagine you own a BMW.
You love driving this car, with its sweet V8 engine and fantastic handling. You feel like you’re riding a bullet train on rails around sharp turns, and it’s fun. Boy is it fun. (Can you tell I’m a cars guy?)
One day your car starts to smell funny. There’s no smoke or engine knocking or anything, but something’s not right.
What do you do?
Do you take it to the Honda dealership and ask them? No! You’re going to take it to the BMW dealership because not all cars are created equal, and you want/need a specialist.
It’s the same way with websites and SEO. Let’s make an SEO-specific analogy.
You have a website with 10 million pages in Google’s index. You’ve been working hard on this site and you are very proud of it. But over time, you’ve noticed that your organic traffic has declined significantly year on year. You need to get that traffic back because the decline is directly affecting your revenue.
So what do you do?
Do you go to any old agency and see if they can help you? Of course not!
You go to agencies and ask them about their experience on your type and size of site, then hire them to work with you.
Enterprise websites (think Zappos, Amazon, or even smaller ecommerce sites) face issues that smaller websites also have, but because of the size and scope of these sites these issues have a much larger effect.
Let’s dig into eight SEO issues that affect enterprise websites more than small websites.
Table of Contents
First, Some Words on Crawl Budget
Every website has a limit to how much the search engines will crawl it. Commonly known as “crawl budget”, the number of pages and amount of data the search engines will access depends on your site’s speed, the quantity and quality of links, your internal linking schema, and much more.
Crawl budget is the most often overlooked part of enterprise SEO. Every point listed below has to do with crawl budget and how these different parts of SEO can affect how well your large website ranks.
Redirect Chains
Every decent SEO knows that a 301 redirect is a vital part of any SEO strategy (regardless of what a Googer might say). Redirects help keep your site clean, consolidate link equity, and help with duplicate content issues (which also cause ranking issues).
One of the most common issues I see on large sites is issues with redirection between HTTP/HTTPS, www/non-www, and trailing/non-trailing slash URLs. Oftentimes, I will see 2-4 redirects happening when in reality only one should happen for each URL.

To diagnose this, use Ayima’s Redirect Checker Chrome plugin or Screaming Frog’s Redirect Chains report. When you find these, “burn them with fire” as Annie Cushing says.
Canonicalization
An issue closely related to redirects is canonicalization. Introduced in 2009, the canonical tag is a behind-the-scenes way to tell the search engines which page they should rank for a specific term. When you are unable to implement redirects to clean up competing pages, the canonical tag is your best friend.
It looks like this:
<link rel=”canonical” href=”https://getcredo.com/pros/seo/consultants/” />
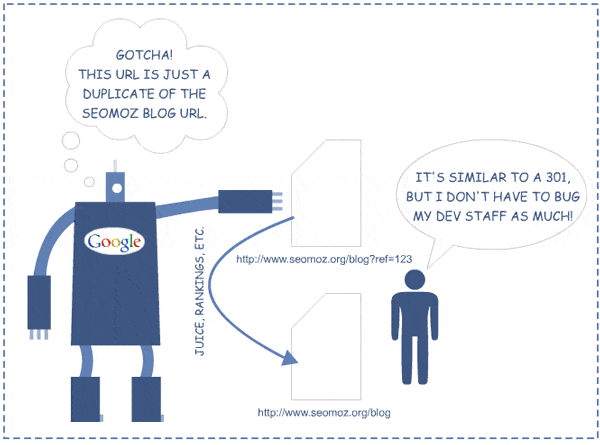
While the canonical tag can be your best friend, it is also a silent killer of websites. Every time the canonical points to a different page than the one the search engines are able to load, it takes them more time to discover the content on your site.
Some of the common issues I see with canonical tags are:
- Pointing all pagination via canonical tag to the first page (when rel prev/next should really be usd)
- Linking to a URL that then canonicals to a different page (this especially kills on pagination and categories)
- Canonical loops (frustrates search engines)
- Canonical to redirect loops (think – canonical to 301 redirect back to the original page). While the page loads, it sends the search engines in loops.
Canonicalization needs to be checked ASAP on enterprise sites and fixed. Sorting it out can show huge dividends.
XML and HTML Sitemaps
Sitemaps feel to me like a relic of the old Internet, yet they are still incredibly important to SEO success. Sitemaps are, bar none, the best way to get the pages on your website discovered because you are literally telling them directly about the content.
XML sitemaps require a different approach on large enterprise sites than smaller websites. The biggest issues I see with XML sitemaps on enterprise sites are:
- Not segmenting sitemaps by page type (eg posts, categories, products) to know where you have indexation issues
- Not using the lastmod directive correctly to prioritize which sitemaps the search engines crawl and when
- Not updating sitemaps often enough. At minimum sitemap cron jobs should be run every few hours to ensure that all new pages are included as quickly as possible
HTML sitemaps are a whole different bear. Ideally, you’ll be able to construct your site in such a way that there is no need for a separate crawl path just for the search engines. Unfortunately, a perfect world does not always exist and often sites that are built with SEO in mind do not convert as well as sites that have the paying user in mind. So while we make every effort to build sites that are SEO-friendly, we also need to balance what the user needs so that they can pay us money!
The biggest issue I see with HTML sitemaps on enterprise sites is the lack of them. Many large site marketers do not take them into account and use them to effectively bring pages up as high in the site’s architecture as possible. I’ll admit that I was not a huge proponent of HTML sitemaps until I saw how effective they are on large sites. Now I am a believer.
Internal Linking
Many websites struggle to interlink their pages in an effective way that gets them all indexed. I wrote this post back in 2012 and did a subsequent Whiteboard Friday about it:
The most common issues I see with internal linking on enterprise level sites are:
- Linking to pages too often that have no ability to rank in the search engines
- Too many internal links that dilute link equity (a good rule of thumb is over 300 on a page is too many)
- Not linking between related pages and back up to categories (to help categories rank for head terms)
Internal linking is a phenomenal way to funnel internal link equity back to the pages that you need to rank for competitive queries.
Pagination
Oh pagination. Pagination used to be a necessary evil for enterprise SEO because no one really knew how to handle it well. With the advent of rel next and prev back in 2011, SEOs finally had a great way to tell the search engines the beginning and end of pagination.
Pagination can be great for SEO because it allows the search engines to access as much content as possible (think legacy products). But it can also hurt SEO when implemented badly.
The common pagination issues I see are:
- Too few products per page which creates so many paginated pages that the search engines do not crawl deep enough (solution: more products per page).
- Not linking deep enough into pagination to get legacy content crawled.
- Linking to the non-canonical pagination (eg /page/1/ when the first page in the pagination is simply /page/)
Site Errors (404s, 500s)
Most SEOs and webmasters know that site errors can have an adverse effect on your website’s rankings. In years past, search engines were actually very fast to drop 404ing content out of the search index. In recent years however I have seen search engines continue to try to recrawl pages that 404 for months after the page disappears.
404s and 500s (server errors) are bad from both a user and search engine perspective. On a small site, a few 404s will not kill you, though you should try to minimize them.
On a very large website, however, 404s and 500s can kill your organic traffic. The challenge becomes in finding all of these so that you can begin to solve them in a systematic way, prioritizing the ones with inbound internal links and largest number then working your way down the list. As you may know, Search Console (formerly Webmaster Tools) only shows you the top 1000. That is not enough when you may have millions of site errors.
On an enterprise site, you need to use your log files and call in the big tools to help you know which erroring pages the search engines are finding most often. You should ask your developers to store the log files and then use a tool like Botify or Splunk to parse them.
Subdomains
Subdomains can be great for SEO because you can have the search engines treat them like a separate website, which can be great for different topics kept on the same domain. About.com is a great example of using subdomains for SEO on an enterprise size website.
Subdomains can also really hurt your SEO when done badly. While the debate around subdomains vs subfolders has generally died down and SEOs generally accept that unless you really know what you are doing you should use subfolders (eg getcredo.com/pros/ instead of pros.getcredo.com), even if you know what you are doing on an enterprise site subdomains can trip you up.
Here are the big issues I see happening with subdomains on large sites:
- Rogue subdomains being indexed and causing duplicate content issues. These should be redirected 1:1 to the main domain.
- Old subdomains with links being redirected to the main domain, but are blocked in robots.txt which means they do not help main domain rank.
- Blog/content sections on subdomains, which I have found to hamper SEO efforts both for content and overall site SEO purposes. These belong on the main domain.
304 Not Modified Status Codes
One of the greatest tools in the enterprise SEO’s toolbelt is the ability to use different status codes to control crawl.
My favorite enterprise SEO trick is the use of the 304 Not Modified status code. Basically, when you have millions of pages that are not updated all the time, the search engines don’t really need to spend all of their time downloading and storing those pages, because what they should prioritize is the fresh content on your site (this especially applies to feed and marketplace driven websites).
Basically, when a document is requested by the search engines, the headers are given a Last-Modified value. The next time Googlebot/Bingbot accesses the page, they leave a If-Modified-Since: in the header. When they come again, if Last-Modified is newer than If-Modified-Since, they will recache. Otherwise they get a 304 Not Modified and move on to find fresh content to index.
What about you?
What issues are you facing with your enterprise sites? What are some of the issues you’ve seen on large sites that I have not covered here?
