Duplicate content. SEOs the world over talk about duplicate content and how it can hurt your website’s rankings in the search engines, but they always conveniently never define what duplicate content actually is.
Because of this, there is a wealth of misunderstanding around the topic. Similar to fresh content and “content marketing”, there are all sorts of people out there (maybe you are one of them!) doing crazy things because you think it will “help your SEO”.
Things like rewriting homepage copy every three months because you hear that it’s good for SEO.
Things like creating content that no one is looking for.
And things like shying away from having useful boilerplate content on your site pages because you think it negatively affects your rankings.
If you haven’t figured it all, all of the above are myths perpetuated by the fact that most SEOs will not take a stand for what something actually means and what it does not. It’s easier to draw broad strokes instead of getting into the nuance.
But if you’ve read anything else on this site (or the two pieces linked to above), you’ll know that I am not one to shy away from the nuance. I believe that we need to think about things deeper and take different changes and strategies into account in context against the others we are doing and what our industry/competitors are also doing.
So today, I am going to attempt to explain what duplicate content is.
Table of Contents
What is duplicate content?
Google’s own site defines duplicate content this way:
Duplicate content generally refers to substantive blocks of content within or across domains that either completely match other content or are appreciably similar. Mostly, this is not deceptive in origin.
While this is a start it ultimately doesn’t really get us to where we need to go with our understanding. You could use the above to say that some legal boilerplate content across the bottom of your site will negatively affect your rankings, which is not the case.
Instead of trying to arrive at a one sentence definition of duplicate content, let’s talk about the key types of duplicate content:
- Same page available on multiple URLs on the same domain;
- Same content on two different websites without a canonical tag (or link back to the original);
- Same SEO elements, different URLs on the same domain
It’s really that simple when we are talking about what will hurt your rankings, so let’s dig into each of these in more detail.
Same full page content, multiple URLs
If your full page’s content (everything on it, including body copy, images, and all) is available on multiple URLs that resolve, return a 200 status code, and canonical to themselves then you are going to have a bad time. When you have this, the search engines do not know which URL to rank and thus they will pick theirs of choice (and it likely will not be the one you want to rank).
These URLs are all seen as different/unique by the search engines (all things being equal):
- http://site.com/url-slug
- http://site.com/url-slug/
- http://www.site.com/url-slug
- http://www.site.com/url-slug/
- https://site.com/url-slug
- https://site.com/url-slug/
- https://www.site.com/url-slug
- https://www.site.com/url-slug/
- https://www.site.com/url-slug?urlparam=1
- https://www.site.com/url-slug/?urlparam=1
Get the picture?
Luckily, if you have that happening on your site you can solve it a myriad of ways:
- Define your canonical (eg https, www, trailing slash) and 301 redirect all of the others there;
- Control URL parameters in Search Console and tell them to ignore ?urlparam with a “Representative content” designation;
- Canonical all URLs with parameters back to the canonical URL in case Google doesn’t respect the above.
As a shorter term change to help your site while you get the above in place technically, you can also usually find instances where you are linking to the non-canonical version that is not then redirecting to the canonical. Change that internal linking and you may see the correct and future canonical URL start ranking instead.
These URLs I point out above are what I call true duplicates, because this is a technical SEO setup issue.
Same content, different domains
This was more of an issue in the past, but it can be an issue in our present day because of either scrapers or because of people publishing their content on multiple websites.
Take a look at Moz and SparkToro founder Rand Fishkin’s blog post about leaving Moz:
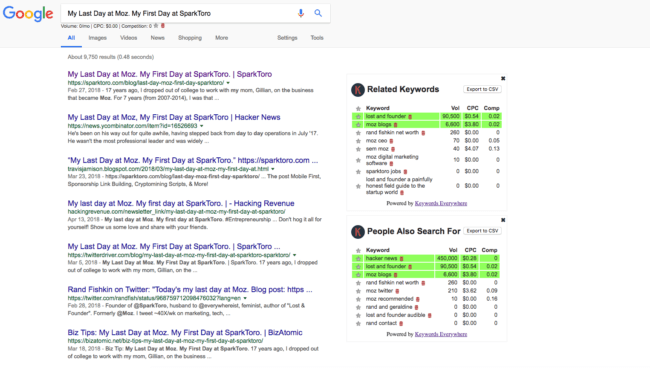
Rand’s content has been scraped by so many different sites. When you search the exact title, you see all of those as well as his post ranking 1st (correctly). Google has become much better at ranking the correct content when there are sites scraping them, but it is still not perfect.
A more common occurrence of duplicate content like this is when:
- Someone posts their content to Medium or another platform to give it more reach, but does not do it properly;
- Someone gives the same piece of content to multiple sites in an attempt to get links back to their site (a practice known as “article marketing” that has thankfully lost steam in recent years).
The most common way this happens is publishing to Medium without using their Import Content tool, which in their words:
If you have a story published elsewhere and would like to import it to Medium, you can use this handy import tool. Using the import tool will automatically backdate the post to the original date, as well as add a canonical link to make sure your SEO won’t be penalized.
What people get wrong sometimes is not using this tool, but rather just republishing the content on Medium (which is a very authoritative domain and thus sometimes ranks very well) without the canonical back or a link back to the original content as the original piece.
Let’s briefly talk about article marketing as well. Some people in the past would produce one piece of content, then either publish it on multiple sites they had access to (which I think has become less common) or would “guest post” it on multiple sites under either their own byline or the site owner’s. This was all in an attempt to get links back to their own or their client’s site with specific anchor text.
When Google Penguin rolled out in 2012, this tactic basically became defunct and risky though you may still receive pitches for guest posts highlighting that the content will be unique. That is a hangover from the old days of SEO.
Same SEO elements, different URLs on same domain
Finally, some sites have what I like to call “near duplicates”. These are usually seen on ecommerce and marketplace websites that generally have thousands to tens or hundreds of thousands of products listed.
Some examples of this are:
- Color variations of products, such as a page for “white nike boost” and “black nike boost”
- Products named the same thing by different creators (such as on Amazon or another marketplace);
Google attempts to address this in their duplicate content guidelines with the following:
Minimize similar content: If you have many pages that are similar, consider expanding each page or consolidating the pages into one. For instance, if you have a travel site with separate pages for two cities, but the same information on both pages, you could either merge the pages into one page about both cities or you could expand each page to contain unique content about each city.
I am talking about a larger issue here which is usually one of a lackluster information architecture to help a) users navigate through the site and b) search engines to organize the site and index all of the products contained on the site.
An ecommerce site might have both of these:
- site.com/product/1234-product-title-best
- site.com/product/9876-product-title-best
These are two separate URLs with different products, but the same elements used primarily in ranking (title, URL, H1, etc). So which should rank for “product title best”?
The answer is who knows.
To solve this problem, the site should build out a category page to target that term. They should create something like “site.com/category/product-title-best” that then links down to both of these products. Both of these products should also link back to the category via breadcrumb links which help the search engines figure out the site’s information hierarchy.
What about you? What misunderstandings do you have or have you had or heard around duplicate content that you would like to debunk?
